· 5 min read
Understanding Large Language Models - Words vs Tokens
A closer look at tokens and why they matter

Large Language Models
Over the last year, large language models (LLMs) have become widely recognized. Remarkably, ChatGPT amassed over 100 million users within just two months and now boasts a daily active user base of over 180 million. Amidst the growing conversation about LLMs, we are frequently asked the difference between “words” and “tokens.”
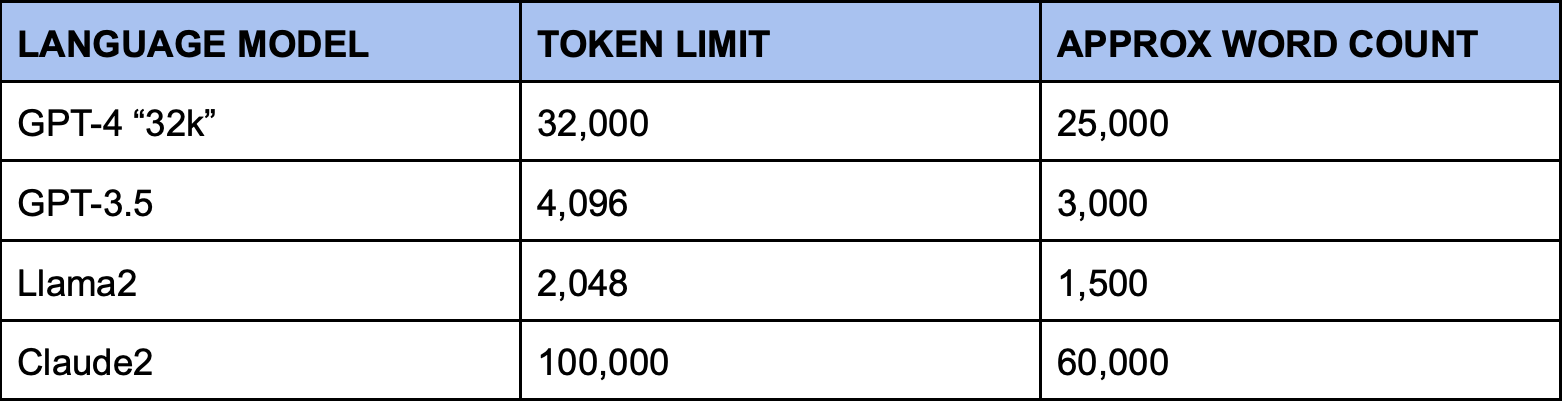
Token counts show up in a variety of discussions regarding LLMs, including in discussion of the size of a model’s training data as well as a model’s context window (GPT-4 now supports a context window of 128k tokens while Anthropic’s Claude2 supports a context window of 100k tokens). Here we explain the difference between words and tokens, and explain the significance of each in relation to large language models.
Words vs Tokens
A word is most likely what you think it is - the most simple form or unit of language as understood by humans. In the sentence, “I like cats”, there are three words - “I”, “like”, and “cats.” We can think of words as the primary building blocks of language; the fundamental pieces of language that we are taught from a very young age.
A token is a bit more complex. Tokenization is the process of converting pieces of language into bits of data that are usable for a program, and a tokenizer is an algorithm or function that performs this process, i.e., takes language and converts it into these usable bits of data. Thus, a token is a unit of text that is intentionally segmented for a large language model to process efficiently. These units can be words or any other subset of language - parts of words, combinations of words, or punctuation.
There are a variety of different tokenizers out there which reflect a variety of trade offs. Well-known tokenizers include NLTK (Natural Language Toolkit), Spacy, BERT tokenizer and Keras. Whether or not to select one of these or a different tokenizer depends upon your specific use case. On average, there are roughly 0.75 words per token, but there can be meaningful differences among tokenizers.
Why Tokens Matter
Simply put, tokenizing language translates it into numbers – the format that computers can actually process. Using tokens instead of words enables LLMs to handle larger amounts of data and more complex language. By breaking words into smaller parts (tokens), LLMs can better handle new or unusual words by understanding their building blocks. It also helps the model grasp the nuances of language, such as different word forms and contextual meanings. Essentially, using tokens is like giving the model a more detailed map of language, allowing it to navigate and understand the complexities of human communication more effectively, even with limited data or in different languages.
Tokens are also a useful form of measurement. The size of text an LLM can process and generate is measured in tokens. Additionally, the operational expense of LLMs is directly proportional to the number of tokens it processes - the fewer the tokens, the lower the cost and vice versa. In an ongoing effort to improve and optimize tokenization methods, different large language models employ different tokenization methods. Consider the sentence,
A nondescript person
There are three words - “a”, “nondescript” and “person”. A simple word-based tokenizer would entail that the number of tokens is identical to the number of words in the sentence and thus there would only be three tokens in the above sentence. A character-based tokenizer would count each character in the sentence, including spaces. Thus, this sentence would have 20 tokens - 2 spaces, and 18 letters. Some tokenizers are context-dependent and so vary depending on the use of the text. Google’s LLM, BERT, relies on such tokenization.
Using the same tokenizer as GPT-4 and GPT-3.5 (and OpenAI’s free online token counter), we can see that the above sentence is broken down into 5 tokens: “a”, “nond”, “es”, “cript”, “person.” In contrast, if we utilize LLaMA’s tokenizer there are 6 tokens.
Turning to the field of law, our domain-specific LLM – the Kelvin Legal Large Language Model, uses our own custom Byte-Pair Encoding (BPE) tokenizer that we have trained on 1T tokens.
Summary
To summarize, the adoption of tokens in LLMs enhances their efficiency in processing extensive and intricate linguistic data; the capacity of an LLM to manage and produce text is quantified by the number of tokens; and the operational expense of running LLMs is directly linked to their token count. Therefore, the efficiency and cost-effectiveness of LLMs are significantly influenced by their token-based processing capabilities.
Tokenization is an important step within the LLM workflow and often involves more than just the simple act of segmenting text. Rather, different tokenization methods are used (at least in part) to help discern and distill underlying linguistic structures.
So the next time you find yourself thinking about tokens and LLMs hopefully you will be able to ask yourself the follow up question, Which tokenization method are they using?

Jessica Mefford Katz, PhD
Jessica is a Co-Founding Partner and a Vice President at 273 Ventures.
Jessica holds a Ph.D. in Analytic Philosophy and applies the formal logic and rigorous frameworks of the field to technology and data science. She is passionate about assisting teams and individuals in leveraging data and technology to more accurately inform decision-making.
Would you like to learn more about the AI-enabled future of legal work? Send your questions to Jessica by email or LinkedIn.