· 5 min read
Understanding Large Language Models - Parameters
The size of a model does not uniformly define its success

When learning about any large language model (LLM), one of the first things you will hear about is how many parameters the given model has. If you look at the chart below, you will notice that there exists a wide range of parameter sizes - a model may have anywhere from 1 or 2 billion parameters to over 1.75 trillion parameters.
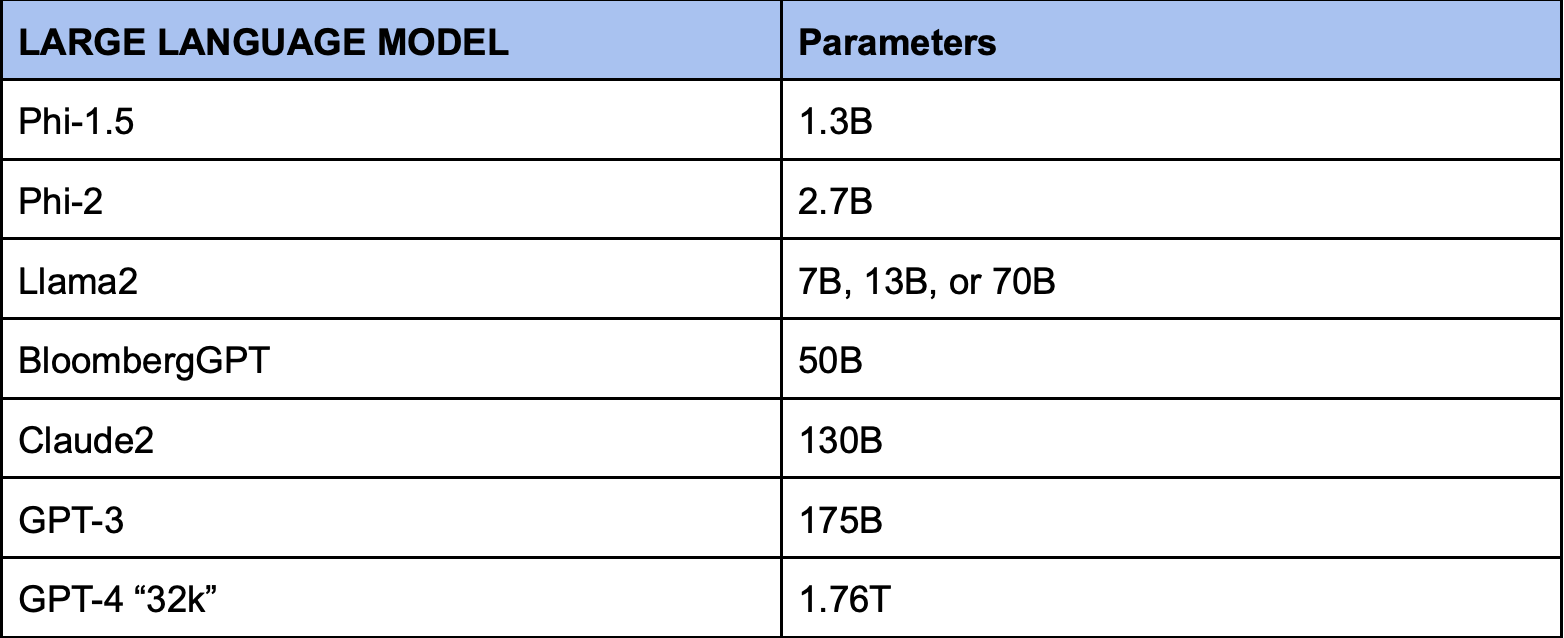
This of course raises the obvious questions - What are parameters and why do they matter? Is it a truism that the more parameters in a model, the better? In an effort to understand and evaluate large language models, let us consider these questions.
What are parameters?
We can think of parameters as internal settings or dials within a large language model that can be adjusted to optimize the process of taking tokens and generating new ones. Much like a sound engineer can optimize the sound quality by turning the dials on a sound mixing board, so too a data scientist can turn the dials within a large language model to optimize its performance.
Recall from one of our previous posts that a token is a unit of text - words, combinations of words, or punctuation - that is formatted such that an LLM can use it efficiently and effectively. When training a large language model, parameters are features of the LLM that are adjusted in order to optimize the model’s ability to predict the next token in a sequence. Consider this simplified explanation of how parameters are trained and function:
A model’s parameters are set to an initial value, either randomly or based on previous training.
The large language model being trained is fed vast amounts of textual data.
As the model is trained, it takes the input and makes a prediction about what the correct output must be.
In training, the LLM compares its prediction to the actual text to see if it predicted correctly or not. The model “learns” from its mistakes and adjusts its parameters if its prediction was incorrect.
This process continues for millions or billions of examples, with the model adjusting its parameters each time and increasing its accuracy in prediction.
Through this iterative process of prediction, error checking, and parameter adjustment, the LLM becomes more accurate and sophisticated in its language abilities.
Is more parameters always better?
The short answer is no.
Admittedly, the more parameters an LLM has, the more “settings” it can adjust to capture the complexities of human language and thus process human language better than models with fewer parameters. So, all things being equal, if model A and model B differ solely in their abilities to process and generate language, then of course you should select the model with superior language processing capabilities.
But in the real world all things are not equal. There are other significant considerations that must be taken into account. Perhaps most obviously, the larger the model, the more costly it is to run. Both the process of training a model and the ongoing maintenance of it require significant computational power and data. It is for this reason that LLMs like GPT-3 or GPT-4 are often developed by organizations with substantial resources.
Running large language models poses an environmental impact as well. A recent study at the University of Massachusetts, Amherst, found that training a large model with 213M parameters can produce more than 626,000 pounds of carbon dioxide emissions. For comparison, the lifetime emissions of the average American car (including the manufacturing of the car) is 126,000 pounds of carbon dioxide - about a fifth of the carbon emissions created by training an LLM with 213M parameters! The larger the model, the more energy consumed and the more subsequent carbon emissions created. Smaller models impose significantly less environmental impact.
You may be worried that opting for a more cost-effective, sustainable model with fewer parameters would undermine the effectiveness and accuracy of an LLM. However, this raises an important point when evaluating LLMs - the size of a model does not uniformly define its success. A given word can have different meanings in different contexts. On average, a larger model tends to be able to distinguish such semantic distinctions, however, a larger model with lower quality training data will not necessarily outperform a smaller more focused model. A model with fewer parameters that is trained on high quality data will outperform a larger model trained on low quality data. In other words, the quality of the data used to train a model is just as important as the size of the model itself. It is this thesis which animates our ongoing efforts to build a LawGPT.

Jessica Mefford Katz, PhD
Jessica is a Co-Founding Partner and a Vice President at 273 Ventures.
Jessica holds a Ph.D. in Analytic Philosophy and applies the formal logic and rigorous frameworks of the field to technology and data science. She is passionate about assisting teams and individuals in leveraging data and technology to more accurately inform decision-making.
Would you like to learn more about the AI-enabled future of legal work? Send your questions to Jessica by email or LinkedIn.